Your web browser is out of date. Update your browser for more security, speed and the best experience on this site.
Event Sourcing: dealing with an eventful past
We keep using the same paradigms for data storage in our applications. The defaults were the defaults for a reason, but they also made sacrifices along the way. These patterns are so engrained in our industry that we forget to question them, even though there may be better solutions to those problems today.
By Hannes Lowette, Head of Learning and Development Axxes.
The trade-offs we inherited
If we look at today's distribution of database use, we see that relational, SQL-based databases still dominate the rankings. And even in our computer science programs, we still teach new developers to normalize their data and to reach for SQL first. That instinct is not wrong, but it is rarely examined.
The structured query language was specified in the 1970s and became an ANSI standard in 1986. The hardware of that era shaped the priorities. While the type of structural data that was being stored, isn't all that different from the present, hard drives were small and expensive. Often a few times more expensive than the computers they were being attached to. In that world, storing any piece of information twice was close to negligent. Normalization was not just a tidy idea, it was an economic necessity.
So the relational model was tuned to make the most of scarce, expensive storage, and it succeeded. When we normalize data we win on three fronts. We win data integrity, because every fact lives in one place and cannot contradict itself. We win consistency, because ACID transactions let us modify that single copy with strong guarantees. And we win disk space, because nothing is duplicated.
But we often forget what we sacrificed to achieve this. The point that often goes unexamined is what we gave up to get them. We sacrificed three things in return:
- Performance: We often query data in complete graphs, across different tables. This requires database joins. Not only is this a sacrifice made in compute, it is compute that is hard to distribute and scale, as it runs in the database engine itself.
- History: In our optimization for storage, our database only represents the current state of the data. Every old version of the records gets lost when the record is overwritten.
- Concurrency: Since we need to guarantee ACID compliance, and data might be touched by multiple writers, we need to deal concurrency issues, either optimistically or pessimistically.
Why the old trade-offs no longer hold
Now ask yourself when you last worried about disk space on a cloud bill. Storage sits near the bottom of the list, well below compute, memory, and network. The single constraint that justified the whole arrangement, the one that made duplication unthinkable, has effectively disappeared.
We accepted slower reads, lock contention, and amnesia about the past in exchange for saving the one resource that has since become cheap. If we are willing to use more storage space again, we can buy back all three of the things we lost: our history, the join load lifted off the database, and an end to fighting over write locks. That is the trade event sourcing helps to achieve, even is we use it on top of a relational DB engine.
What event sourcing is
Take a look at almost every software system wel build. A command arrives, a request for the system to do something, whether from a button press, a message on a bus, or an API call. Code gets called to do the work, usually by reading the current state, applying logic, and writing something back. At the end, the system communicates that something has happened. Let's call those outputs events.
It helps to view these three things through time. A command speaks about the future, it is a request that has not yet been honored. State represents the present, how the system's data looks right now. An event speaks about the past: something that has already happened and, since we don't have a time machine, cannot be changed. State, in this view, is how our system passes information to its future self, so the next command has something to work against. The question event sourcing asks is whether state is the best message to pass forward, or whether we can do better by being explicit about the events that produced that state in the first place.
The state of a system is always the result of the events that have taken place in a system in the past. This points to an asymmetry at the heart of the idea. If you keep the events, you can always rebuild the state by replaying them in order. The reverse is not true: given only the final state, you cannot reliably recover the events that produced it. State is a lossy compression of history, and once you have compressed, you cannot decompress.
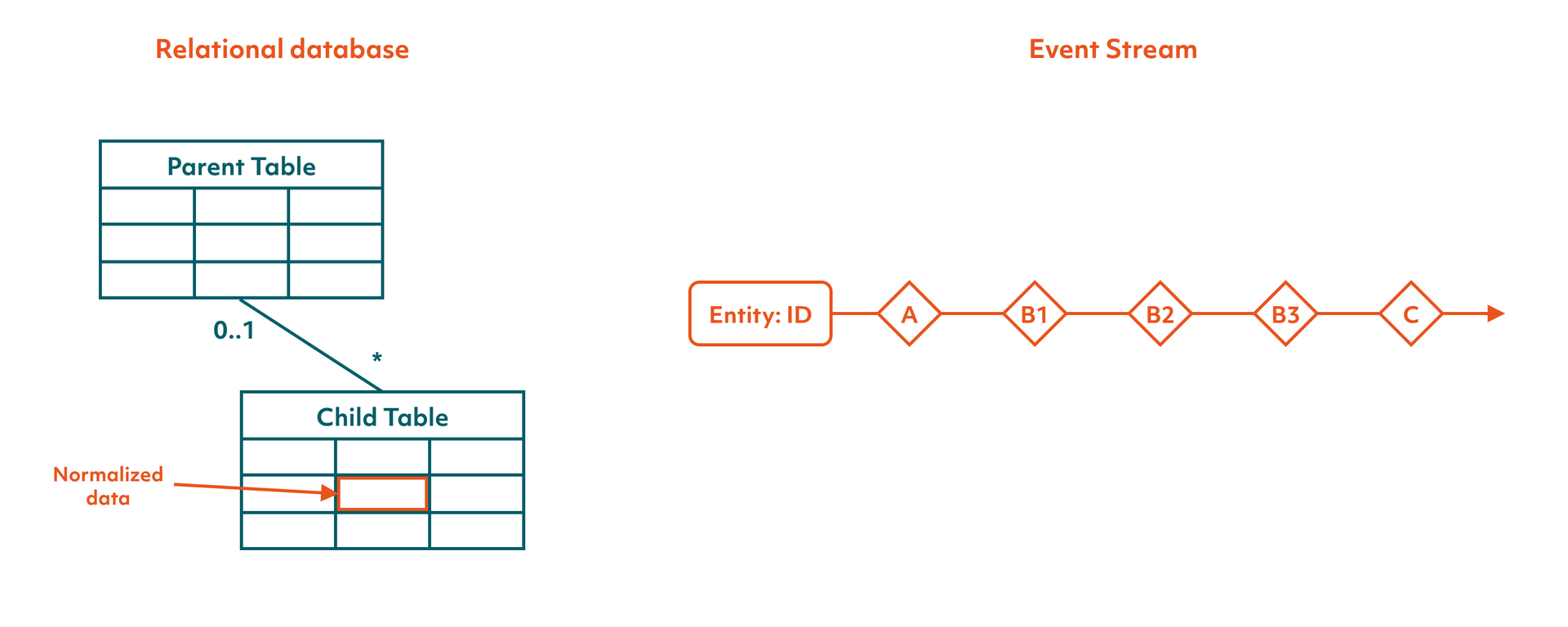
So event sourcing stores the events. Instead of a normalized set of tables that represent an entity and its children, where records get overwritten, we treat that entity instance as a stream of past events. When data changes, we append its events to the stream in order. The benefits follow directly. We only append to the end of a stream, so writes need no locks. We never overwrite, so we keep the full history. And we lift the join load, because reconstructing an entity is a sequential read of one stream rather than a fan-out across tables. The cost we now choose to spend is increased storage, since the data is more verbose and carries redundancy, a trade most systems can easily afford today.
The command handler life cycle
Because we no longer store state, handling a command differs a little behind the scenes. A command handler is still just a function in a class, and its first job is familiar: it locates the entity it needs to act on. But now we don't have the state of said entity materialized in our storage system. So rather than loading a row, we fetch every event in that entity's stream, and we replay them to rebuild the entity's state in memory. The handler then runs its logic, and instead of writing back to the state table, it produces new events. These new events get appended to the end of the stream. Subsequent command for the same entity will get an updated stream, because the new events get fetched as well. That is the whole cycle: locate the stream, fetch its events, replay them into state, run the logic, append new events.
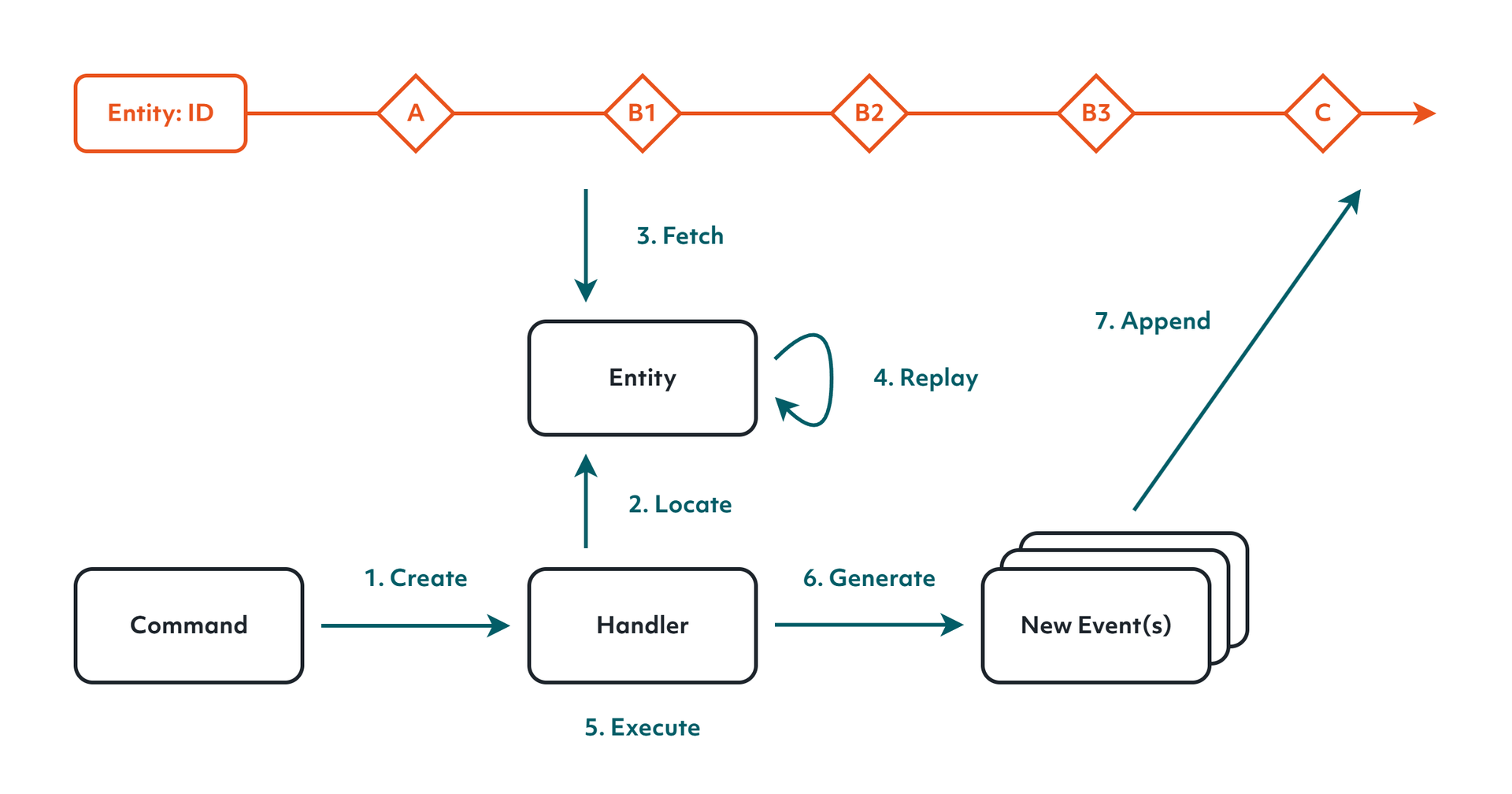
In practice, you do not write any of this by hand on a daily basis. A framework handles the fetch and replay, and your handler reads much like code you would write against an ORM today. You can hand-code your own event sourcing framework, or use an existing one, but the code reads very familiar to any developer that uses an ORM today.
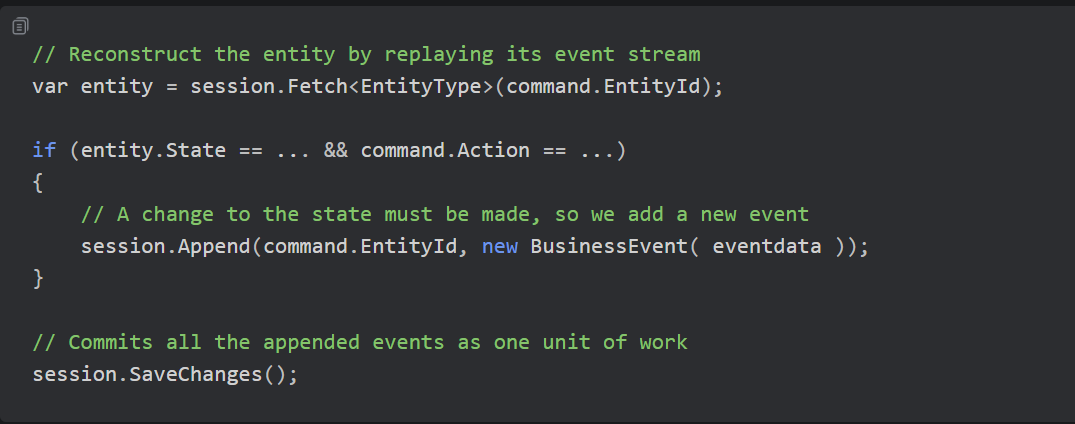
A question that comes up often is why we store events rather than commands, since the command arrived first. There are two good reasons. First of all, much of the heavy lifting, including side effects such as calls to external systems, happens when processing the command. Replaying commands would re-run those side effects every time. And secondly, handler logic is the code most likely to change: replay the same command after the business rules have changed, and you get different events than originally, which corrupts the historical record.
A stored event, by contrast, is a fact that was true when it was written, so replaying it needs no validation and no side effects and is mostly a matter of setting fields on an object. Several thousand events can replay in a few milliseconds. The events themselves are best modeled as an immutable data structure, which mirrors a deeper truth: they are immutable over time in the system as well.
Storage of events can be thought of in a very simple way, and requires the following fields:
- Stream ID: The entity ID the event belongs to.
- Sequence Number: The order of the event within this entity's history.
- Event Data: The (serialized) representation of the event.
- Event Type: The type of event. This helps deserialization and filtering.
- Metadata: We can add additional data such as timestamps, correlation ids, etc.
Conceptually this is an append-only table that you can put in a relational database if you like, and because it requires no joins it is easy to tune. And adding a unique constraint across the stream id and the sequence number helps with solving concurrency issues between thread trying to write to the same stream.
In order to replay events to reconstruct the entity's state, all we require is some simple apply methods on the entity class. These take in the events that need to be replayed, and will in turn modify the state of the entity instance. You'll end up with one apply method per event type, which handles the state change of this event for that entity. Those apply methods are side effect free and local, so opening one shows exactly how a given event changes the entity. Someone not familiar with the codebase can get an understanding of the model by reading them.
How it fits with CQRS
Event sourcing is frequently mentioned alongside CQRS and domain-driven design. The three are separate ideas, but they fit together unusually well.
Let's start with Command-Query Responsibility Segregation, or CQRS. The ideas of CQRS can be summed up briefly as such:
- Command side: The command handling side of the system is not responsible for returning results, merely processing commands against the state of the system.
- Query side: The query side of the system returns results, but doesn't change the state.
- Models: In order to optimize performance on both sides, we use different models for query and command.
- Actualization: To bring the query side's database (the read store) up to date, we need an actualization mechanism. The most efficient way to do this is to write projections that handle events raised by the command side.
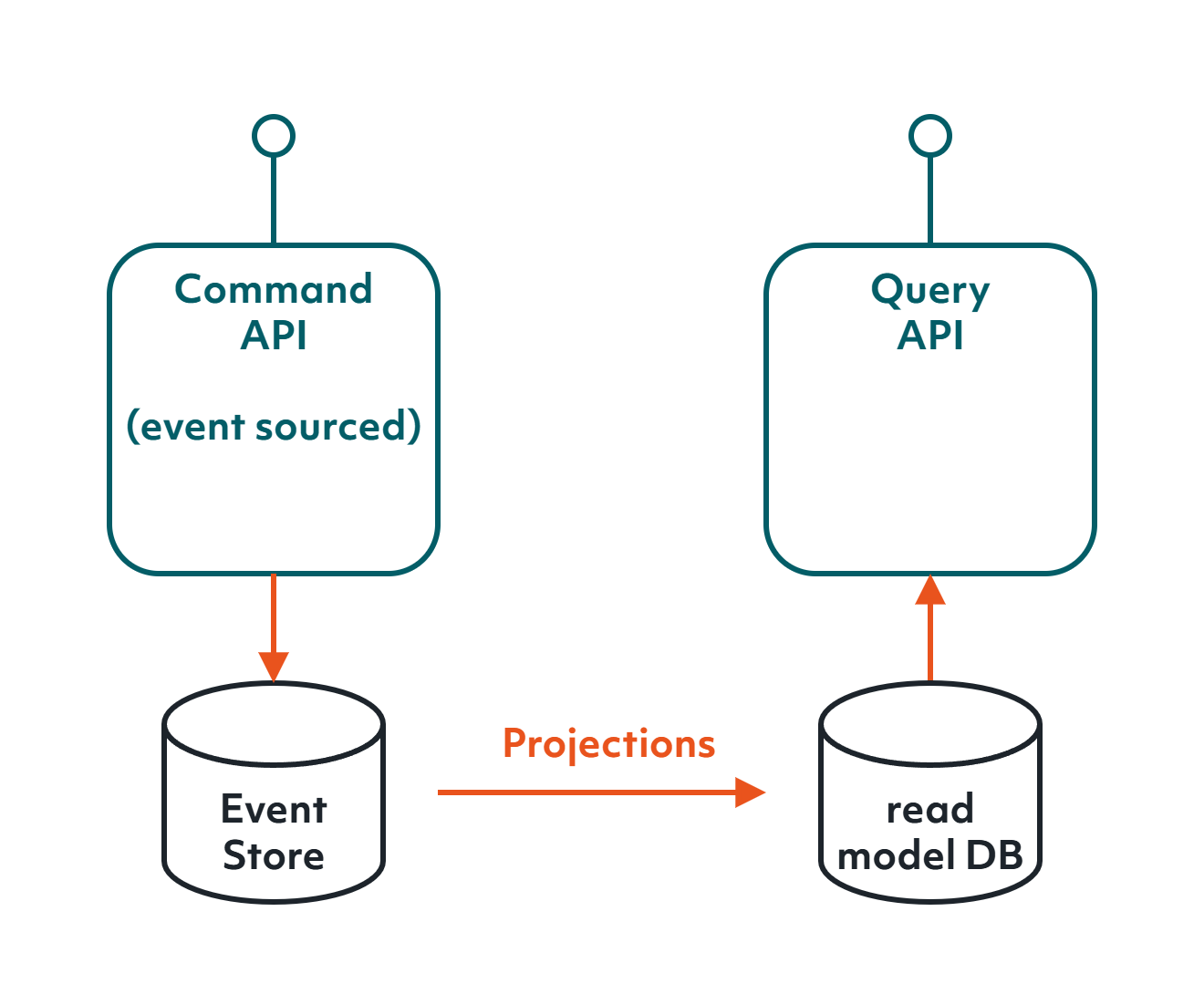
If we write our command side against an event sourced model, then our business events that get stored there can be the same events that feed the projections to update the read store. This is exactly why event sourcing and CQRS fit so well together, as it removes the practical dissonance between the events and state. We will use the exact same business events to write to the command side's event stream as the ones we will raise to feed our projections.
How projections work
The mechanism that builds a query side table's contents is a projection. A projection is a piece of code that subscribes to specific events, filtered so that it only sees the ones it cares about, and uses them to create, update, or delete records in a read model. The read model can be a document store, a relational table, or anything else. This way, the projection turns events into a data shape that is convenient to query.
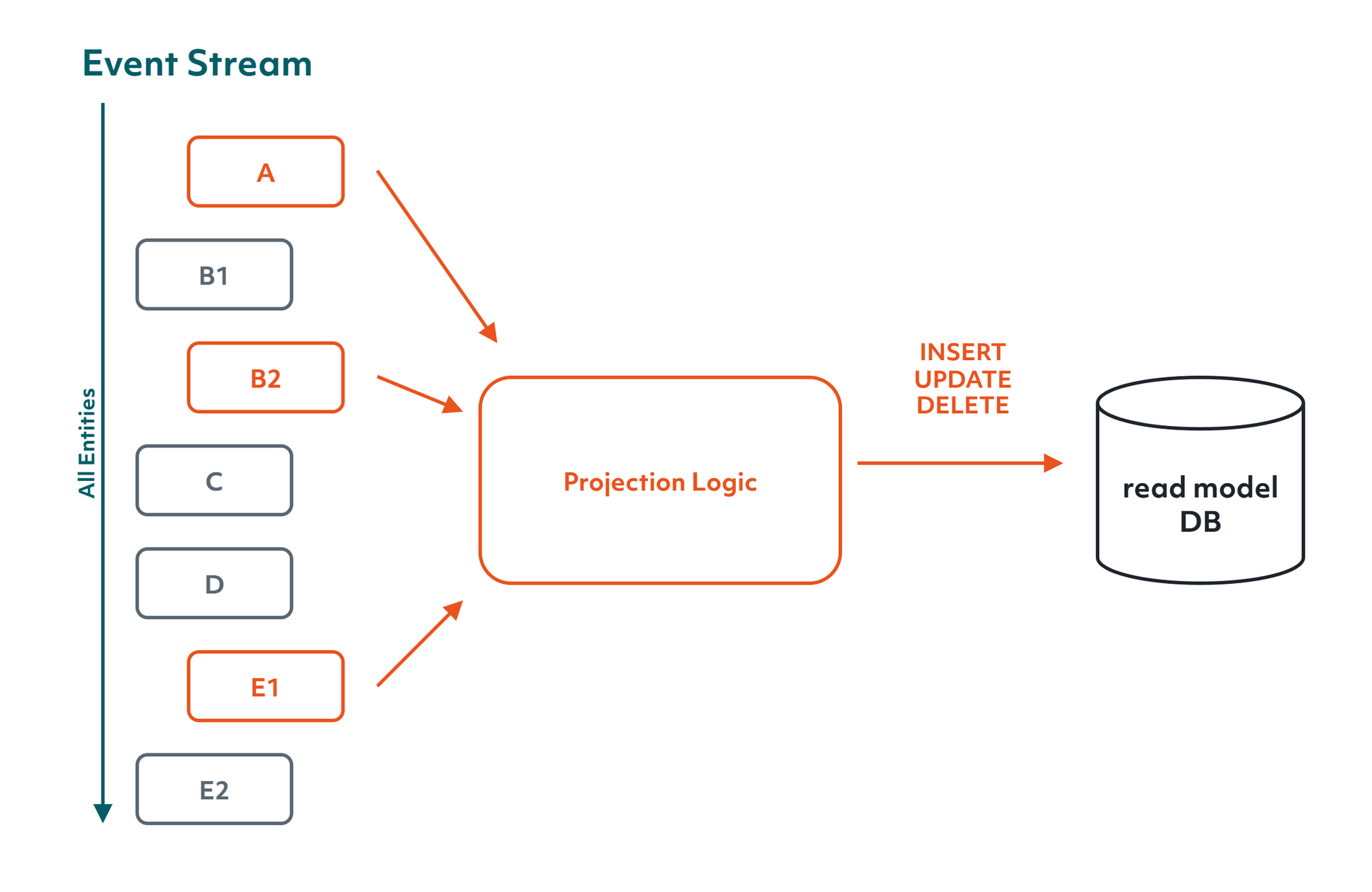
There is a lot to be said about projections, and how they can be tuned in a system. But I think there are two properties of projections that matter most here.
The first is isolation. Every projection has no effect on anything else in the system, and its only responsibility is to feed a particular (set of) table(s) in the query store. That data is owned by the projection, and nothing else writes to it. This makes the inputs and outputs of a projection nicely side effect free, and makes evolving the code and the system as a whole very predictable to do.
The second is that projections answer a problem that was painful with normalized databases: new demands on old data. Suppose the business asks for an insight that needs information we never thought to store in a queryable form. With a normalized schema we would write migration scripts and often resort to guesswork to backfill the tables. With event sourcing, the history is already there in the events. We write the projection we would have written anyway, point it at the existing stream, and let it replay from the beginning, ending with a read model built from real history rather than reconstructed estimates.
The same property makes projections easy to change. If the logic needs to change, you discard the read table and rebuild it from the stream under the new logic. Because a projection only writes to its own read model and has no effect on the command side or on other projections, rebuilding one is safe, and that part of the system becomes low risk to evolve.
Why this suits domain-driven design
Domain-driven talks about letting the business domain dictate the architecture and the code. The original philosophy is to let the code, as much as possible, reflect the real language, terminology and behaviors of the business that it supports. Not only does this have an effect on the resulting code, but it also shapes how conversations between developers and domain experts from the business side of the organization are held. You have probably seen teams gathered around a wall of sticky notes. Techniques like event storming and event modeling use exactly that practice to map a business process before any code is written, use a color-coded vocabulary for commands, events, projections, and read models.
And that's exactly where it fits so neatly. In those workshops, each sticky note corresponds to a concept in the system, and with event sourcing each note becomes a class more or less one to one: command notes become commands, event notes become events, read-model notes become projections. There is no intervening step where someone decides how to flatten all of this into a normalized schema, and that translation, from the language of the business to the language of tables, is where meaning gets lost. Event sourcing removes this friction. The model you discussed with the domain experts is the model you write down in code, which is precisely what domain-driven design is trying to achieve.
Isolation and performance tuning
A full-blown CQRS system runs as a collection of smaller responsibilities: command handlers, projections, a query API with a read store, event subscriptions for integrations, etc. The beautiful part of this is, that every bit of code runs in relative isolation, with very limited side effects. This means the parts of a CQRS system can be tuned independently, since the operations have no effects on other parts of the system or its peers.The default mode for a CQRS system is 'eventually consistent' between the command and the query side. For business or performance reasons, we can deviate from that strategy for certain types of operations. We could either force immediate consistency, at the cost of slower command processing. Or we could defer the processing of a projection until its get queries, mitigating the upfront cost of populating a read store. Both should only be done in specialty cases, but depending on your setup entirely possible to achieve.
Long streams raise a related concern. An entity that accumulates millions of events would be slow to replay on every command. Snapshotting solves this: when the stream becomes long, we compute the entity's state up to a point in the stream and save it separately. This means the next command can load the snapshot first and replay only the events after that point.
Why this works in the age of AI
The case for event sourcing has always rested on bringing the business domain and the code closer together. Two consequences of that closeness now pay off when working with AI models.The first is the absence of side effects. The core building blocks: the command handlers, the projections, the event subscriptions, etc. are all free of side effects within the system itself. The code doesn't get reused in other code paths either. Code like this is straightforward to build a context around, which makes it easy to evolve, whether the person changing it is a human developer or an AI model. And it's this lack of hidden coupling that mitigates the risk that a local change breaks something elsewhere. Projections can be discarded and rebuilt, which gives a model a safe space to make changes whose effects are easy to verify by replay. Predictable, isolated code is exactly the kind that automated tools handle well.
The second is the closeness to the business language. Because commands, events, and projections map directly onto the way the business describes its own processes, the names in the code are the names the domain experts use. When you use a spec-driven framework to manage your features in a software system, those specs will match closely with the effective code that implements these specs. Again, what helps a junior dev find their way in our system, is also what helps an LLM to make the correct changes within the context it is given.
Where to start
You do not have to build any of this from scratch, and you should not. Mature frameworks and purpose-built data storage engines exist across most ecosystems. Here are some examples:
- Marten: A .NET document database, event store and projections system on top of Postgres SQL.
- Axoniq: A JVM framework for event driven development, including event sourcing.
- Emmett: A TypeScript event sourcing framework.
- Python eventsourcing: Python has several event sourcing packages.
- Kurrent: Formerly called Event Store, is its own engine with clients in many languages.
- EventSourcingDB: This is a relatively new append only, purpose-built event store in Go. It has client libraries in many languages. It is fully supported in OpenCQRS on the JVM.
As for the question you are probably asking yourself: when do I adopt this? The strongest signal is not technical. Event sourcing becomes a natural way to structure your code once you become familiar with it. The real win, however, arrives when you can talk to your business people in terms of commands and events while modeling their processes. At that point translating those conversations into code is almost mechanical, because every concept maps across. That requires the people to think this way first. The hardest problems are always people problems, not technical. Get the conversation right and the architecture follows. It'll benefit the people on the team as well as the (AI and other) models they use to build their applications.

Hannes Lowette
Head of Learning & DevelopmentHannes is a developer, a coach and a father of 3.
In .NET development, he has always had a passion for performance, databases, distributed systems and large scale applications. But most of all, he likes playing devil’s advocate in technical discussions by drawing the ‘it depends’ card.
As a coach, he is enthousiastic about knowledge sharing, personal growth and building careers. All this while keeping in mind that the pace needs to be sustainable.
In his free time, when he’s not building LEGO® castles with his kids, he likes to spend time building guitars, playing chess or poker, tasting whisky and doing all round geeky stuff.
You can occasionally find him on an afterparty stage at PubConf or with Dylan Beattie & the Linebreakers.
Do you want to get your whole team on board with event sourcing?
Or do you want support in building your first event sourced application?