Your web browser is out of date. Update your browser for more security, speed and the best experience on this site.
Van zoeken naar vinden: AI als jouw documentdetective
Waarom kost het in zoveel organisaties meer tijd om één document terug te vinden dan om het te maken?
Dagelijks worden rapporten, policies en offertes geproduceerd, waarna ze verdwijnen in een wirwar van mappen waar kennis langzaam vervaagt. Traditionele zoekfuncties, gebaseerd op exacte keywords, schieten vaak tekort: wie zoekt op vergoeding vindt niets terug wanneer in het document compensatie staat. Wat als we een systeem hadden dat wél begrijpt wat we bedoelen, synoniemen herkent en vragen beantwoordt alsof we het aan een collega stellen?
Van zoeken naar vinden, AI als jouw document detectieve
Bij de meeste organisaties kost het vinden van één document meer tijd dan het maken ervan. Elke dag worden er opnieuw rapporten, policies, offertes en talloze andere documenten geproduceerd. Ze belanden op een filesysteem en verdwijnen in een doolhof van folders en subfolders waar waardevolle kennis langzaam vervaagt. Het terugvinden van specifieke documenten of informatie wordt zo een uitputtende zoektocht die nauwelijks vooruitgaat, vaak met heel wat frustratie tot gevolg.
Traditioneel zoeken werkt op basis van keywords: het systeem kijkt of dezelfde woorden uit je vraag letterlijk in documenten voorkomen. Dat werkt prima als je precies weet welke termen je moet gebruiken, maar het faalt zodra je zoekvraag en de tekst andere woorden gebruiken voor hetzelfde idee. Wie zoekt naar de kilometervergoeding in de carpolicy achter het woord “vergoeding” vindt niets terug, omdat het woord “compensatie” wordt gebruikt. We missen een zoeksysteem dat begrijpt naar wat we op zoek zijn, een systeem dat synoniemen kan herkennen en vragen kan beantwoorden alsof we het aan een collega zouden vragen.
Embeddings: de basis van zoeken op betekenis
Semantisch zoeken pakt dit veel slimmer aan. In plaats van naar woorden te kijken, probeert het te begrijpen wat je bedoelt. De kern daarvan zijn embeddings.
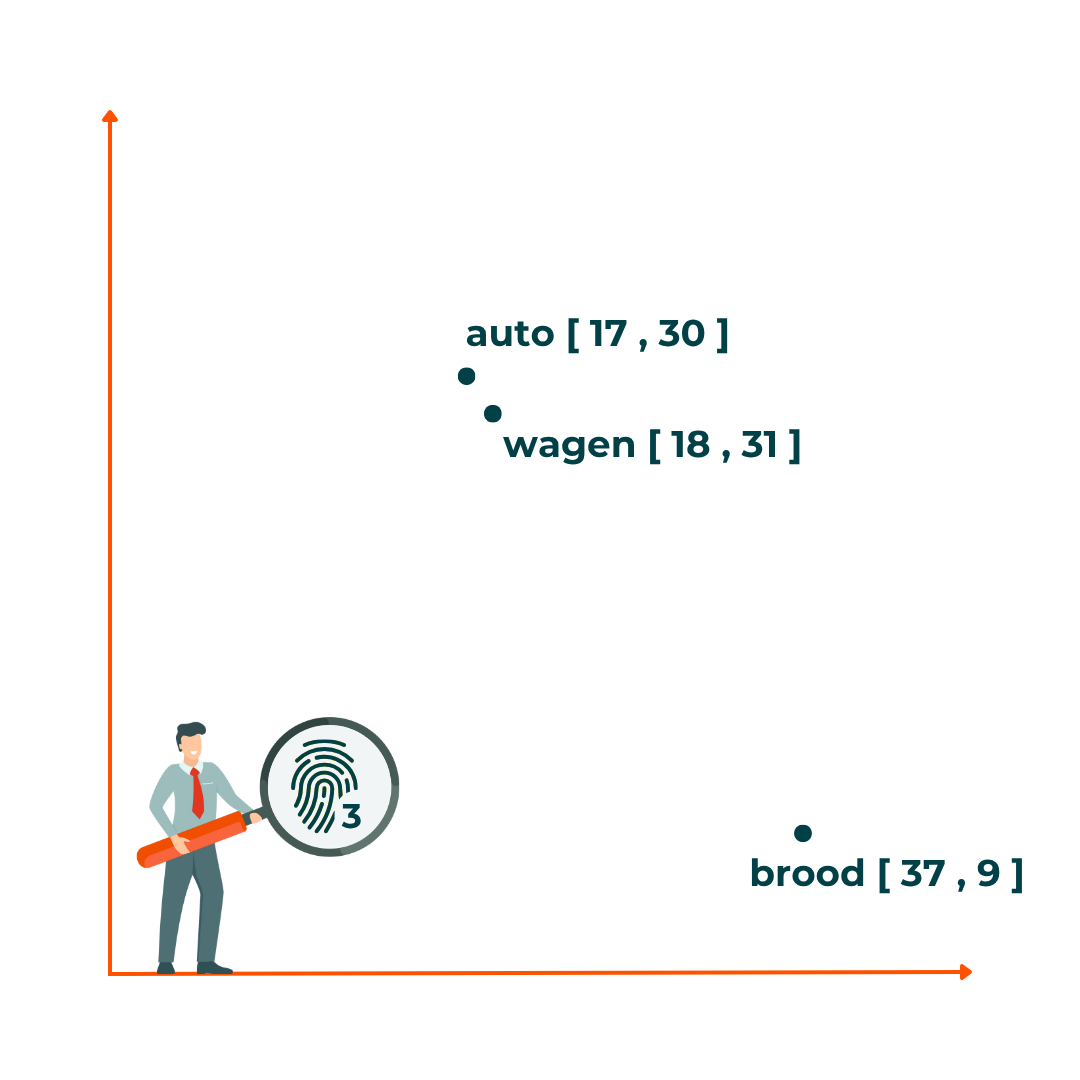
Embeddings zijn een soort numerieke vingerafdrukken van betekenis. Een embeddings-model zet woorden, zinnen of hele documenten om in een vector: een lange lijst met getallen, soms wel duizenden. Een computer kan aan de hand van de vectoren heel snel uitrekenen welke vectoren dicht bij elkaar liggen en welke veraf. De computer kijkt niet naar wat de getallen zijn, maar hoe dichtbij of ver ze van elkaar liggen. Die getallen zijn zo gekozen dat teksten met een vergelijkbare inhoud dicht bij elkaar liggen in een multidimensionale ruimte, terwijl teksten die helemaal niet op elkaar lijken ver uit elkaar liggen. Zo weet het model bijvoorbeeld dat het woord “auto” en “wagen” inhoudelijk verwant zijn, waardoor hun embeddings dicht bij elkaar liggen. “Auto” en “brood” daarentegen hebben weinig met elkaar te maken, wat maakt dat hun embeddings ver uit elkaar liggen. Wanneer we kijken naar zinnen wordt opgemerkt dat de embedding van een vraag dicht in de buurt ligt bij de embedding van het antwoord op die vraag. Dit maakt dat semantisch zoeken perfect is om informatie op te zoeken die aansluit bij een specifieke vraag, ook als die helemaal anders geformuleerd is.
Door embeddings te gebruiken vindt je zoekresultaten die aansluiten bij de betekenis van een vraag, waardoor de juiste informatie sneller wordt gevonden.
Chunking: de sleutel om documenten bruikbaar te maken voor AI
Om relevante stukken informatie uit documenten op te halen op basis van een vraag, moeten we er eerst voor zorgen dat onze documenten bruikbaar zijn voor het AI-systeem. De techniek die dit mogelijk maakt, heet chunking.
Chunking betekent dat je grote documenten knipt in kleine, logische stukjes,“chunks”, die apart kunnen worden geëmbed en teruggevonden. Waarom dit nodig is? Grote AI-modellen kunnen maar een beperkte hoeveelheid tekst tegelijk 'lezen' en onthouden. Door te knippen, zorgen we ervoor dat we ze precies de informatie geven die nodig is om de vraag te beantwoorden, en niet het hele rapport van 50 pagina's.
Er zijn veel verschillende manieren van chunking, elk met zijn voor- en nadelen. Hier even 3 kort uit de doeken gedaan:
- Fixed-size chunking: je knipt de tekst in blokken van bijvoorbeeld 300 karakters. Simpel, snel, maar het kan woorden, zinnen of paragrafen doormidden hakken.
Bijvoorbeeld:
Chunk 1: “Werknemers hebben recht op een thuisw”
Chunk 2: “erkvergoeding van €2 per dag.” - Recursieve chunking: je probeert eerst volgens natuurlijke grenzen te splitsen (hoofdstukken, paragrafen, zinnen). Pas als een stuk nog te groot is, knip je verder. Dit levert veel natuurlijkere chunks op.
- Semantische chunking: hierbij laat je een AI-model zelf bepalen waar de betekenisvolle scheidingslijnen liggen. De chunks volgen dus écht de inhoud, niet de lengte. Ideaal, maar ook het duurst om te genereren.
Ook de chunk-grootte is van belang. Te kleine chunks zorgen voor contextverlies, terwijl te grote chunks zorgen voor irrelevante informatie.
RAG: Antwoorden genereren op basis van je eigen informatie
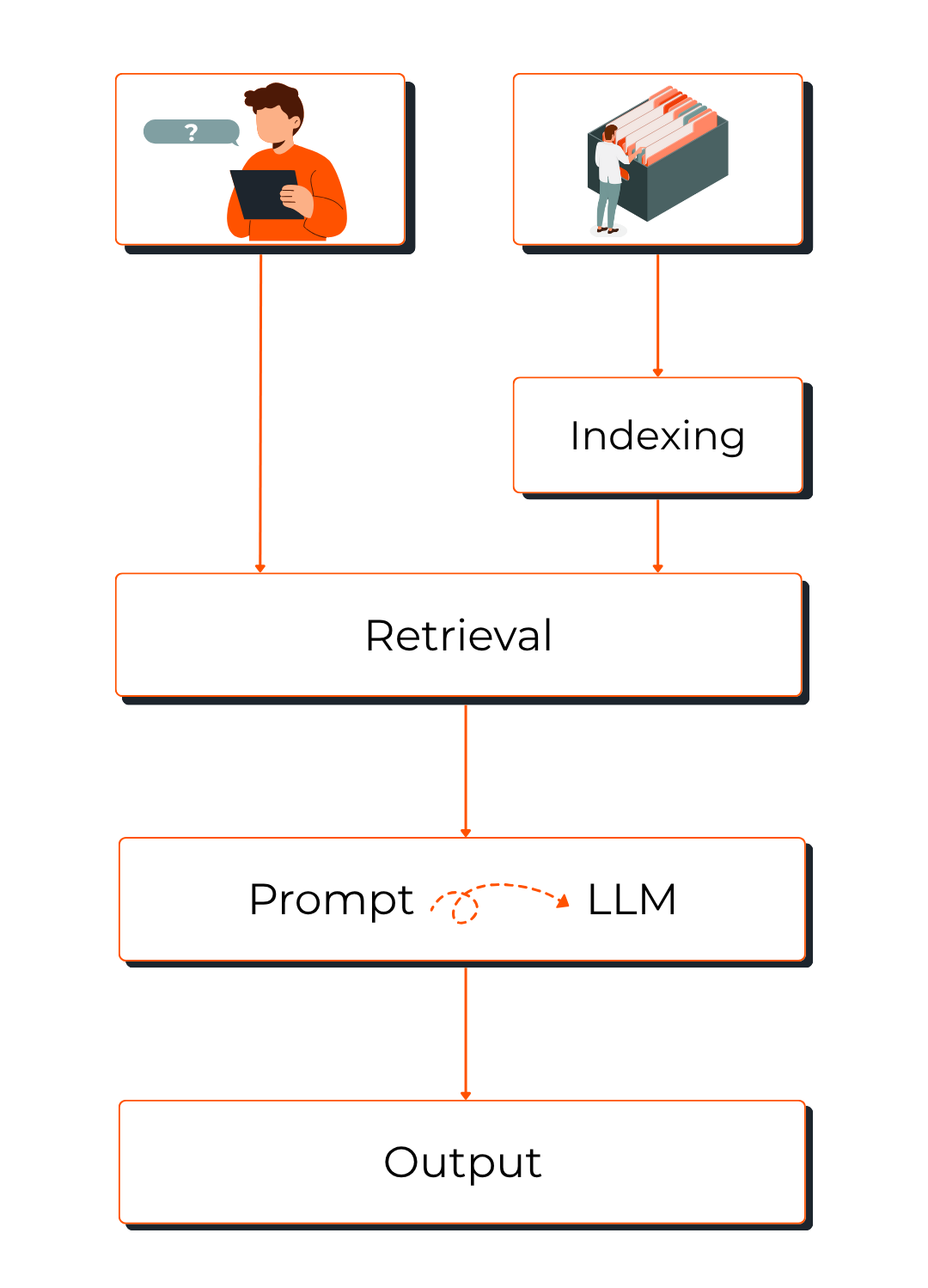
Als je semantisch zoeken, embeddings en chunking samenbrengt, krijg je de basis van wat we vandaag kennen als een RAG-systeem: Retrieval-Augmented Generation. Het is een architectuur die een taalmodel combineert met een externe kennisbron. In plaats van het model alles te laten “verzinnen” uit zijn trainingsdata, gaat een RAG-systeem relevante informatie ophalen en gebruiken als context voor zijn antwoord.
In de praktijk werkt het zo:
- Je interne documenten worden gechunked en geëmbed
- Je stelt een vraag.
- Het systeem maakt een embedding van die vraag.
- Die embedding wordt vergeleken met de embeddings van de chunks.
- De meest relevante chunks worden opgehaald (retrieval).
- Het taalmodel gebruikt die context om een betrouwbaar antwoord te genereren (generation).
Stel, je stelt de vraag: “Wat was de totale prijs in onze offerte aan Bouwbedrijf X vorig jaar?” Het systeem zet deze vraag om in een embedding en vergelijkt die met de embeddings van al je interne document-chunks. De meest gerelateerde stukken tekst, bijvoorbeeld de offerte van dat jaar, worden opgehaald. Deze relevante fragmenten worden vervolgens als context meegegeven aan het taalmodel, waardoor het model een precies en gefundeerd antwoord kan genereren. Zo kan het systeem bijvoorbeeld teruggeven dat de totale prijs €148.500 was, inclusief specificaties uit de oorspronkelijke offerte.
Met andere woorden: het taalmodel verzint het antwoord niet meer, maar baseert het op de informatie die jij zelf beheert.
En dat is precies waar RAG de klassieke tekortkomingen van LLM’s oplost:
- Het vermindert hallucinaties, omdat de AI echte context krijgt.
- Het houdt je kennis up-to-date, omdat je eenvoudig nieuwe documenten toevoegt.
- Het zorgt voor transparantie: je weet precies uit welke documenten het antwoord komt.
Semantisch zoeken begrijpt je vraag, embeddings geven betekenis een vorm, chunking maakt informatie bruikbaar en RAG brengt alles samen tot een systeem dat niet alleen slim, maar ook betrouwbaar en controleerbaar is. Het is de revolutie in documentbeheer die komaf maakt met de tijdrovende zoektocht. De volgende keer dat je uren bezig bent met het zoeken naar die ene offerte, weet dan dat er een detectieve is, gebouwd op AI, die het werk in seconden voor jou kan klaren. Benieuwd hoe dit er voor jouw documenten kan uitzien?