Your web browser is out of date. Update your browser for more security, speed and the best experience on this site.
Event Stream Processing met Apache Kafka
Van zodra je de deur uitwandelt, merk je dat de wereld nooit stilstaat. Een auto passeert, het stoplicht springt op rood en een alarm loeit op de achtergrond. Het zijn kleine en grote evenementen, die doorheen de dag duizenden keren plaatsvinden. Ook online gebeuren er continu zaken die heel wat data genereren. Door Apache Kafka te gebruiken voor je event streaming krijg je niet alleen zicht op al die gebeurtenissen, maar kun je ook risico’s en opportuniteiten detecteren.
Als bedrijf gebruik je doorgaans niet één applicatie, maar een waaier aan digitale producten en systemen. Event streaming is een handige manier om je applicaties en bedrijfsprocessen te laten gelijkstromen. Zo kan je die tools op dezelfde manier laten werken. Een beetje zoals in een webshop, waar elke gebeurtenis chronologisch wordt afgehandeld zonder dat er onderweg informatie verloren gaat.
Event Streaming
De data die je bij event streaming capteert kan van verschillende bronnen komen. Denk bijvoorbeeld aan databases, sensoren, mobile devices, cloud services, software applicaties.
Je kan deze stream van events zowel real-time als met terugwerkende kracht behandelen door er bijvoorbeeld manipulaties, processen of reacties op uit te voeren. Vervolgens kan de event stream doorgestuurd worden naar een bestemming. Ook hier zijn er verschillende mogelijke bestemmingen, zoals databases, data warehouses, messaging queues of softwareapplicaties. De data van je event streaming kan je duurzaam bijhouden, zodat je bepaalde events nadien altijd opnieuw kan afspelen. Het is dan ook verstandig om een licht formaat te hanteren om de gegevens op te slaan.
Event streaming zorgt voor een continue flow aan data die je op meerdere manieren kan interpreteren. Hierdoor kan de informatie op het juiste moment op de juiste plek aankomen.
Waar gebruik je event streaming voor?
Bij financiële transacties zoals op de beurs, bij banken of verzekeringen is het noodzakelijk dat deze transacties real-time worden verwerkt. Event streaming kan hier een goede oplossing zijn die ook toelaat om zeer veilig met data om te gaan.
Een ander relevant voorbeeld is het monitoren van het verkeer door het real-time processen van data, waardoor je een actuele blik he
bt op de staat van het verkeer. De throughput van deze data kan heel hoog zijn, doordat je duizenden of miljoenen voertuigen volgt die geregeld hun positie en andere data doorsturen. Je kan ook ad-hoc analyses uitvoeren op de data, waardoor je inzichten kan creëren na de feiten.
Machines en sensoren die verbonden zijn met het internet vormen ook een interessante bron van data. Die gegevens kan je zowel ad-hoc als real-time analyseren. Zo zou je bijvoorbeeld het aantal mensen in de kamers van een gebouw kunnen bijhouden en personeel uitsturen voor een betere doorstroom waar nodig. Ook hier kan je ad-hoc analyses uitvoeren om je gebouw onder andere anders in te richten of gerichter wegwijzers plaatsen, omdat men bijvoorbeeld vaak een verkeerde route volgt.
Bij webshops of fysieke winkels kan je klanteninteracties en orders verzamelen en er eventueel op reageren. Als een klant je webshop bezoekt, iets in zijn winkelmand legt en dan de site verlaat, kan je bijvoorbeeld een mail sturen om de klant te vertellen dat de boodschap nog niet is afgerond. Ook als een order is geplaatst, als de betaling gedaan is of als het pakketje wordt verstuurd, kun je dankzij event stream processing een mail sturen.
Nog een voorbeeld? Patiënten monitoren en veranderingen voorspellen. Aan de hand van onder andere beelden en data kan je met event streaming voorspellen of er zich een noodsituatie voordoet en of je eventueel moet ingrijpen. Doordat je met event streaming bijna real-time kan monitoren, kan dit van levensbelang zijn voor je patiënt.
Het samenbrengen van verschillende departementen van je bedrijf wordt mogelijk gemaakt door het connecteren, opslaan en beschikbaar maken van data. Met event streaming kan je je data op een dataplatform laten leven. Het heeft als voordeel dat je niet meer meerdere malen je gegevens hoeft te produceren en door te sturen naar verschillende instanties. Je kan het simpelweg op je dataplatform produceren en meerdere malen consumeren.
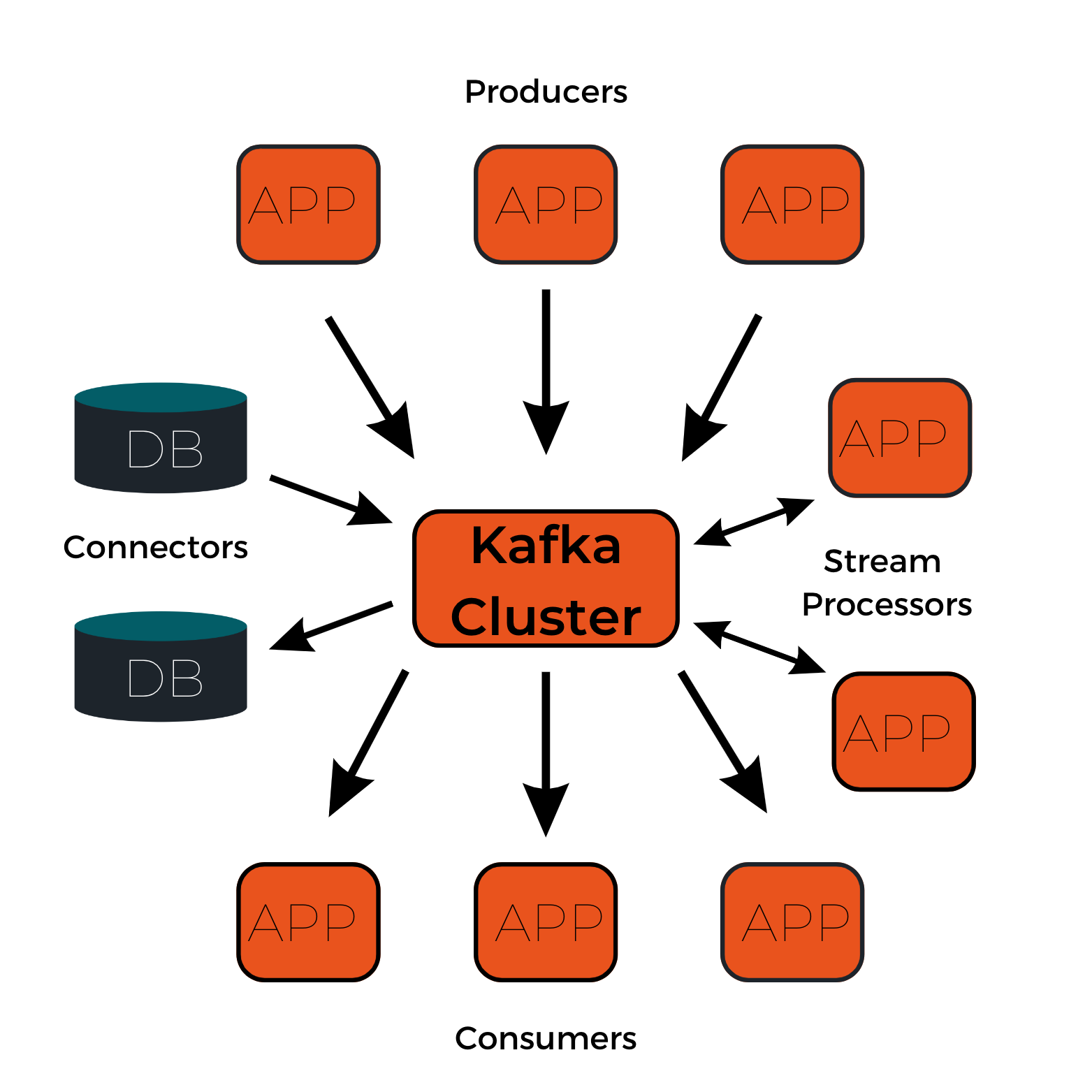
Event streaming platforms
Om succesvol end-to-end te kunnen event streamen heb je drie belangrijke zaken nodig:
Je moet kunnen publiceren naar en abonneren op event stream mogelijkheden. Daarbij moeten continue import van en export naar andere systemen centraal staan.
Er is nood aan het duurzaam en betrouwbaar opslaan van event streams voor onbepaalde duur.
Je moet processen van event streams kunnen raadplegen terwijl ze gebeuren of met terugwerkende kracht.
Het is uiterst belangrijk dat deze onderdelen op een gedistribueerde, schaalbare, elastische, fouttolerante en veilige manier zijn geïmplementeerd. Een voorbeeld van zo’n platform is Apache Kafka, dat intussen al meer dan 10 jaar bestaat.
Kafka kan uitgerold worden op bare-metal hardware, virtuele machines en containers. Het kan zowel on-premise als op de cloud draaien. Er zijn zowel self-managed als fully managed services beschikbaar. Bij Axxes hebben we onder andere ervaring met AWS MSK (Amazon Managed Streaming for Apache Kafka).
Met Kafka kan je zonder problemen aan event streaming doen. De principes van Kafka steunen erg op de drie onderdelen van een event streaming platform, waardoor je veel data kan processen zonder er verder veel over na te hoeven denken. Verder is Kafka losgekoppeld van je applicatie, waardoor je naadloos kan consumeren van en produceren naar je platform.
Belangrijkste concepten en terminologie
Een event registreert dat er “iets gebeurt” in de wereld of in je bedrijf. Het wordt ook wel record of message genoemd. Conceptueel gezien heeft een event een key, value, timestamp en optionele metadata headers.
Ook de termen “producer” en “consument” zul je geregeld horen vallen wanneer het over event streaming gaat. Een producer is een client applicatie die events publiceert naar Kafka, een consumer is dan weer een client applicatie die subscribed op deze events. In Kafka zijn producers en consumers volledig ontkoppeld van elkaar. Dit is een kernprincipe van het platform, waardoor het zo schaalbaar is.
Producers moeten met andere woorden niet wachten op consumers, en kunnen bijgevolg zo veel data produceren als ze willen. Producers en consumers kunnen hierdoor ook apart opgeschaald worden. Kafka zorgt voor allerlei garanties, zoals de mogelijkheid om events exactly-once te processen.
Een topic is de plaats waar events worden opgeslagen en geprocessed. Je zou een topic kunnen vergelijken met een folder in een filesysteem. De events zijn dan de files in die specifieke folder.Topics zijn altijd multi-producer en multi-subscriber. Events kunnen zo vaak uitgelezen worden als nodig is, want in tegenstelling tot traditionele messaging systemen worden events niet verwijderd na consumptie.
In Kafka definieer je hoe lang je data bij wil houden, ook wel bekend als retentie, door een per topic configuratie. Dit kan zowel door een tijdslimiet in te stellen als een limiet over de grootte van de data die op het topic mag bestaan. Kafka’s performantie blijft effectief constant, zelfs als je data zeer lang bewaart.
Partities zijn een onderdeel van een topic. Een topic wordt gepartitioneerd, wat wil zeggen dat een topic verspreid wordt over een aantal “buckets” die op de Kafka Brokers staan. Deze gedistribueerde locaties zijn belangrijk om schaalbaarheid te halen. Het laat toe client applications zowel tegelijkertijd te lezen van en te schrijven naar meerdere brokers. Wanneer een nieuw event wordt uitgestuurd, wordt het toegevoegd aan een topic-partitie. Events met dezelfde key worden naar dezelfde partitie gestuurd, waardoor Kafka kan garanderen dat eender welke consumer van een topic-partitie altijd de events met die specifieke key in chronologische volgorde zal lezen.
Om je data fouttolerant en highly-available te maken kan elk topic gerepliceerd worden. Dit kan over geo-regions of datacenters heen, waardoor er altijd meerdere brokers een kopie van je data bevatten in het geval er bijvoorbeeld iets verkeerd gaat of je onderhoud wilt uitvoeren op de brokers. Een typische setting in productie is een replicatiefactor van drie. Dit wil zeggen dat drie kopieën van je data tegelijkertijd bestaan. Deze replicatie is op het niveau van een topic-partitie.
Hoe werkt Kafka nu?
Kafka is een gedistribueerd systeem dat bestaat uit servers en clients die via een high-performance TCP-netwerk protocol communiceren.
Het platform wordt uitgerold als een cluster van één of meerdere servers die over meerdere datacenters of cloud regions kan spannen. Sommige van de servers vormen de storage layer en worden ook wel brokers genoemd. Andere servers worden uitgerold als Kafka Connect, zodat zij continue data kunnen importeren en exporteren als events streams. Daarnaast kunnen ze Kafka integreren met bestaande systemen zoals relationele of NoSQL databanken of andere messaging systemen, maar ook andere Kafka-clusters.
Clients laten je toe gedistribueerde applicaties en microservices te schrijven die parallel, geschaald en fouttolerant event streams lezen, schrijven en processen. Zelf bij een netwerkprobleem of een machinale fout garandeert Kafka dat de events juist afgehandeld worden.
Kortweg is Kafka een open-source gedistribueerd streaming systeem. Het is makkelijk te integreren met andere applicaties en technologieën en dankzij de grote throughput en schaalbaarheid van Kafka is het een ideaal systeem als backbone voor je platform. Dat grote bedrijven als Airbnb, LinkedIn, Netflix, The New York Times en Microsoft op Kafka vertrouwen toont dan ook aan dat het een robuust en betrouwbaar systeem is.
Op de hoogte blijven van onze Insights?

Jorgi Leus
Java ConsultantBenieuwd hoe je een gratis iPhone kan bemachtingen?
Altijd al willen weten hoe fraudeurs te werk gaan op een e-commerce pagina?