Your web browser is out of date. Update your browser for more security, speed and the best experience on this site.
How Kubernetes Operators effortlessly keep stateful applications running
It is not always easy to develop an application and keep it operational. Preferably, the application is available at all times, but it must also be able to handle peak loads, application crashes, and updates with limited downtime, for example... Fortunately, there are technical solutions like Kubernetes Operators that solve these issues in a generic manner.
It is not always easy to develop an application and keep it operational. The application is preferably available at all times, but it must also handle peak loads, application crashes, and updates with limited downtime, for example. Fortunately, there are technical solutions that solve this in a generic manner. Just ask Niels Claeys!
Niels presented a keynote on Kubernetes Operators at Haxx Digital Edition. It is essentially a method for packaging, deploying, and managing stateful/complex applications within Kubernetes. This may be a mouthful, but once you know what you can use them for, it will make your work a lot easier!
Kubernetes has become increasingly popular for around eight years now. It is an open-source tool for deploying and managing containers. A container contains the code (functionality) and all the associated dependencies and the configuration. In other words, containers are a virtual representation of your operating system, unlike virtual machines (VM), which are a virtual representation of your hardware. Because only a small layer of the kernel has been implemented each time, there is a much smaller overhead than in VMs, Essentially, Kubernetes is the perfect way to build, deploy, and scale production-worthy applications in containers.
Numerous things must have been arranged to deploy applications in a production environment: automatic handling of crashes, configuration management, automated updates and rollbacks, scaling based on the load, determining on which host machine the application must run .... For stateless applications, Kubernetes contains the building blocks for implementing all these matters. Thanks to Kubernetes Operators, you can also work with stateful applications, but we will discuss this later.
A stateless application does not contain data that must be remembered when the container is rebooted/updated. Just like a blackboard that is erased after use. A typical example is a web application that retrieves its data from a database.
The automated aspect makes Kubernetes so attractive. Without making it overly technical, Kubernetes ensures that your application will continue to operate, whatever happens. Let us illustrate this using an example!
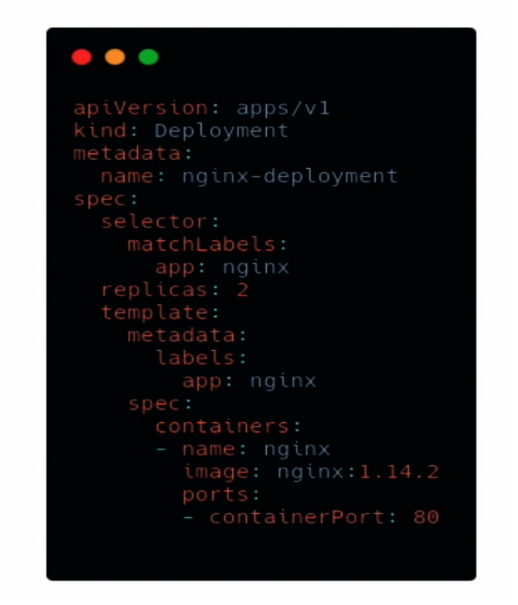
An example: the deployment of an NGINX application
This is an example of the deployment of an NGINX application. As you can see, we want to run two instances of this application in our cluster. Kubernetes will ensure that two instances are operational at all times. If one crashes for any reason, Kubernetes will ensure that a second is launched.
Interaction with Kubernetes is usually done using the kubectl command line (CLI), but you could also contact the API server directly. As a user, you usually define the Kubernetes objects in YAML files because this is more legible and easier. Internally, Kubernetes presents its objects in JSON format.
Besides the API server, the controller is another critical component within Kubernetes. As the name reveals, this controller determines what must happen at which time. To do this, the controller compares the current situation of the cluster to the desired situation. If the situation is not the same as defined in the JSON configuration, it will be adjusted. We call this mechanism the control loop. If only one NGINX instance would be running in our example, the controller will create a second instance.
Each object you have defined in Kubernetes (pod, deployment, service, ...) has a controller which contains the logic to determine what must happen if the current situation deviates from the desired situation. These built-in controllers make it easy to deploy/update/run stateless applications automatically.
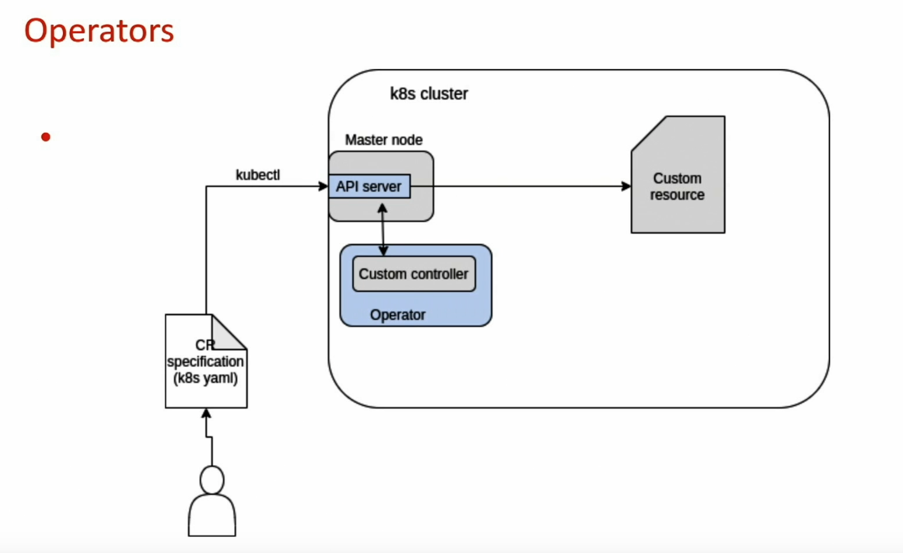
Kubernetes Operators for stateful applications
If your application contains ‘state’, for example, if it is a database, things become more difficult. These applications do not always start with the same blank sheet. In this case, you must be able to place the domain logic somewhere (such as creating backups or a possible replica as a master before you conduct an upgrade). You do not want to do this manually, but want to incorporate it somewhere. In this case, we use an operator that expands the functionality of Kubernetes.
An operator contains two important aspects:
- A custom resource: this is merely a declarative description of your object with the various parameters/configuration. It contains all information needed to manage the application.
- A controller that will determine what must happen to get the Kubernetes cluster in the right condition based on your resource. This means that it is an own implementation and an expansion of the Kubernetes API. Of course, it also uses the so-called ‘control loop’, but contains its own logic to resolve a difference in condition. The current condition of the cluster is compared to the expectations of the user to determine which steps must be taken to get there.
This is mainly important for complex, stateful applications. In this case, the primitive objects that exist within Kubernetes are insufficient. You also want to embed the domain logic within Kubernetes itself to ensure you do not need to handle anything manually yourself.
You can compare it to creating objects with the primitives of your programming language when using an object-oriented programming approach. In the same manner, you will create an operator in Kubernetes that will combine the primitives of Kubernetes to create the desired domain logic.
This makes it possible, for example, to simplify the upgrading of a complex application: if you would do this using the built-in objects of Kubernetes, you may need to create four of five different resources in a specific order. You will only need to create one custom resource with the operator, after which it will automatically ensure that all underlying objects are created in the right order.
Many companies have defined their own operators. Examples are databases or queueing systems, as well as cloud providers. This makes it easier for people who are used to managing infrastructure in the cloud using Kubernetes. The S3 Operator of AWS, for example, makes it possible to manage S3 buckets without any knowledge of AWS. As a user, you will only need knowledge of the relevant custom resource to use it within Kubernetes. You must define and register the main parameters with Kubernetes, after which the operator will ensure that the connection with AWS is established and the right S3 Bucket will be created.
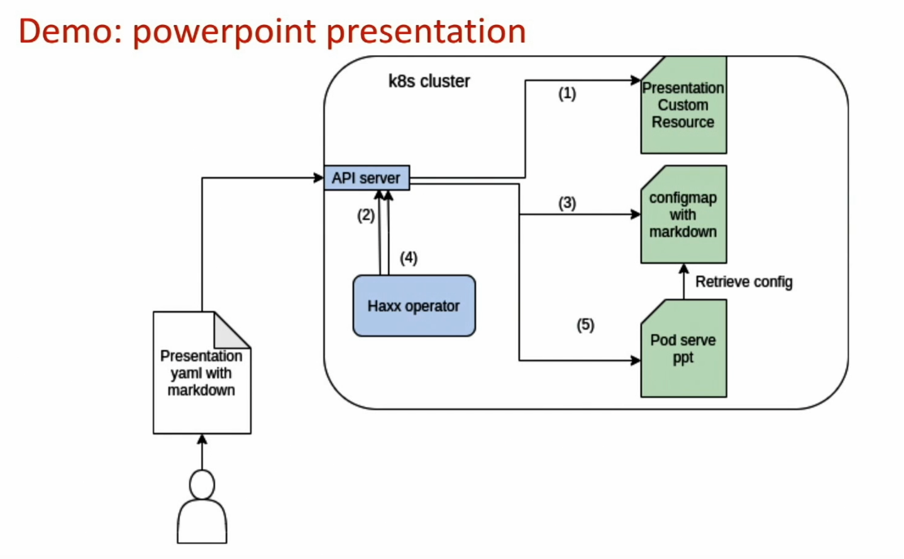
An example: automatically converting Markdown documentation into slides
At Haxx Digital Edition, Java coach Niels Claeys showed how he can automatically convert his presentation defined as Markdown into slides using Kubernetes Operators. The full code of this example can be checked here.
Niels first defined the presentation object (Presentation yaml with markdown). This describes the slides and their content. Based on this input, the operator (the Haxx operator) determines what it must do to convert the input into a slideshow.
It will need to use the configuration and save it in a config map (configmap with markdown). A pod, a container (Pod serve ppt) will be created that will use the configuration and convert it into a presentation. We use the Operator SDK, a framework developed by Red Hat, to create the operator. The Operator SDK makes it possible to create operators and deploy these on a Kubernetes cluster.
The operator is written in Go, just like the Operator SDK. Niels first created the project structure by initialising the project: he indicated what his operator is, which name it will have, and what the domain is. Numerous files were subsequently created with boilerplate logic when writing an operator.
The next step was creating the API: the presentation object and the underlying controller logic. In this case, the presentation object was a stuct that only contained a string. The controller is somewhat more complex: it includes the logic of what must happen if a new presentation object is created. In Niels’ example, a new config map and the associated pod must be created.
This information can be found in the Reconcile function. This function first requests the current condition of the cluster to decide what must happen. For example, it checks whether a new config map must be created or whether the existing one must be updated.
There is also the pod – the container – that will convert the Markdown logic into a presentation in this case. In this case, the existence of the pod is verified again to enable it to be created if necessary.
You first require a cluster to be able to subsequently deploy it on Kubernetes. This can be done using MicroK8s, for example, a cluster operating locally. Once the operator is deployed, a number of objects are created immediately: a deployment, a service, and the custom resource definition. The latter makes it possible to register our presentation object with Kubernetes.
Less manual work
Thanks to Kubernetes, it becomes a lot easier to manage applications, because things are automated as much as possible. There is less manual work because Kubernetes contains logic to reboot, scale, and update applications... Thanks to Kubernetes Operators, this existing functionality can also be expanded based on the needs of our organisation. This is primarily important for ‘stateful applications’: applications that do not necessarily start with a blank sheet when you use them.
Benieuwd naar meer Axxes Insights?
